Posted by Oscar Wahltinez, Developer Programs Engineer In this blog post, we’ll focus on the key Responsible AI concepts that develop...
Text embeddings have been shown to be very effective for a variety of machine learning tasks. They are a powerful tool that can be used to represent the meaning of text in a way that can be understood by machines. Here are some examples of how embeddings are used:
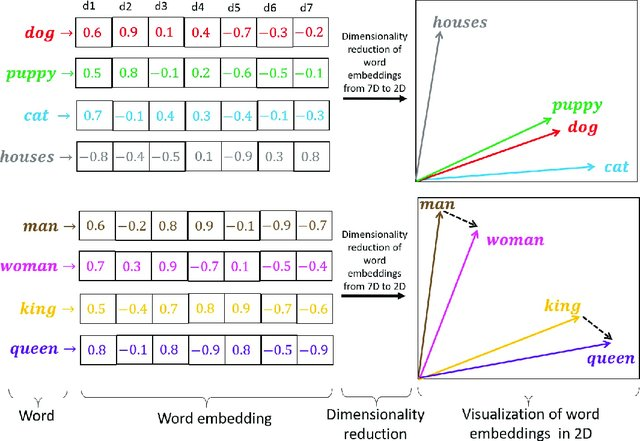
Text embeddings are a very powerful way to numerically represent text as a vector of real values. Once the text has been converted into a numerical representation, it can be processed using mathematical operations that can be used as a proxy for a crude, approximate understanding of the meaning of the text; for example, using distance as a proxy for similarity.
In the context of machine learning, a text embedding is a way to convert a word, sentence or entire document into a list of numbers i.e. a vector representation. Text embeddings are used to represent the meaning of words in a way that can be understood by neural networks. As mentioned earlier, they are often used in natural language processing tasks such as text classification, sentiment analysis, and machine translation.
Text embeddings are created by feeding a large corpus of text into a neural network. The neural network learns to associate each word with a vector representation that captures its meaning. These vector representations can then be used as a proxy for the meaning of sentences and documents.
A well-known example of how word embeddings can be produced is the word2vec architecture, which shows that numerical representations of words could be treated as mathematical vectors, including not only distance but also general-purpose vector operations such as addition and subtraction. One of the more traditional examples of this is the distance and direction between the vectors representing "man" and "woman" are roughly equivalent to the distance and direction between the vectors representing "king" and "queen".
Sentence embeddings and document embeddings are similar to word embeddings in that they are vector representations of text. However, they capture the meaning of a sentence or document as a whole, rather than the meaning of individual words.
Sentence embeddings are typically created by feeding a large corpus of text into a neural network. The neural network learns to associate each sentence with a vector representation that captures its meaning. These vector representations can then be used to represent the meaning of sentences in a variety of machine learning tasks.
Document embeddings are created in a similar way, but they use a larger corpus of text and a more complex neural network. This allows them to capture the meaning of entire documents, rather than just individual sentences. Document embeddings are often used for tasks such as topic modeling and document classification.
A neural network can produce sentence embeddings by first feeding the sentence into a word embedding layer. This layer will convert each word in the sentence into a vector representation. The vector representations of the words are then fed into another neural network, but here's a big challenge in natural language processing – each sentence might have a different number of words. To cope with this, traditionally one would pad or truncate the inputs – however, one of the key recent discoveries was the use of attention and transformers to handle variable-sized input focusing only on the important part of a sentence or document to compute an embedding representation.
Although the attention mechanism and transformers play a big role in most existing large language models (at least at the time this was written), we will not cover the details of how that works in this blog post.
Now that we have covered the theory, we can dive into how embeddings can be computed using TensorFlow with just a handful of lines of code.
First, we need a set of sentences that will be turned into embeddings. To do this, I asked Bard to give me ten short, fun facts about a handful of topics:
chair: - The word "chair" comes from the Latin word "cathedra," which means "seat of authority." - The first chairs were made of stone or wood, and were often very ornate. - The first mass-produced chairs were made of metal and used in factories and industrial settings. - The most expensive chair in the world is the Throne of Dagobert, worth an estimated $10 million. - The world's largest chair is located in the town of Owatonna, Minnesota, and is 30 feet tall. - The world's smallest chair is only 1.5 inches tall and is made of plastic. - The average person spends about 6.5 hours per day sitting down. - Sitting for long periods of time can increase the risk of obesity, heart disease, and diabetes. - Standing desks are a popular way to reduce the amount of time people spend sitting down. - There are over 100 different types of chairs in the world. automobile: - The first automobile was invented in 1886 by Karl Benz. - The first mass-produced automobile was the Ford Model T, which was introduced in 1908. - The world's most expensive car is the Bugatti Chiron Super Sport 300+, which costs $3.9 million. - The world's fastest car is the Hennessey Venom F5, which can reach speeds of up to 270 mph. - The most popular car color in the world is white. - The most popular car brand in the world is Toyota. - The average American spends about $9,000 per year on their car. - The average American driver will drive about 13,500 miles per year. - The average American will spend about 10 years of their life driving. - There are over 1 billion cars in the world. water: - Water is the only substance that exists on Earth in all three states of matter. - Water covers 71% of the Earth's surface. - The human body is made up of about 60% water. - The Earth's oceans contain about 97% of all the water on Earth. - The average person drinks about 2 liters of water per day. - The average person uses about 80 gallons of water per day. - Water is essential for life. - Water is used in many different industries, including agriculture, manufacturing, and energy. - Water pollution is a major problem in many parts of the world. - Water conservation is important to ensure that everyone has access to clean water. tree: - Trees are the longest living organisms on Earth. Some trees can live for thousands of years. - Trees provide us with oxygen to breathe. - Trees help to regulate the Earth's climate. - Trees provide us with food, shelter, and medicine. - Trees help to prevent erosion. - Trees beautify our surroundings. - Trees provide homes for animals. - Trees help to reduce noise pollution. - Trees help to improve air quality. - Trees are a symbol of strength and resilience. camera: - The word "camera" comes from the Latin word "camera obscura," which means "dark room." - The first cameras were used by ancient Greeks and Romans to project images of the sun and stars. - The first camera that could record images was invented in 1839 by Joseph Nicéphore Niépce. - The first digital camera was invented in 1975 by Steve Sasson. - The first digital camera was very large and heavy, weighing over 8 pounds. - The first digital camera could only store 10 photos. - The first digital camera cost over $100,000. - Today, digital cameras are small, lightweight, and affordable. - Today, digital cameras are used by millions of people around the world. - Digital cameras have revolutionized the way we capture and share images.
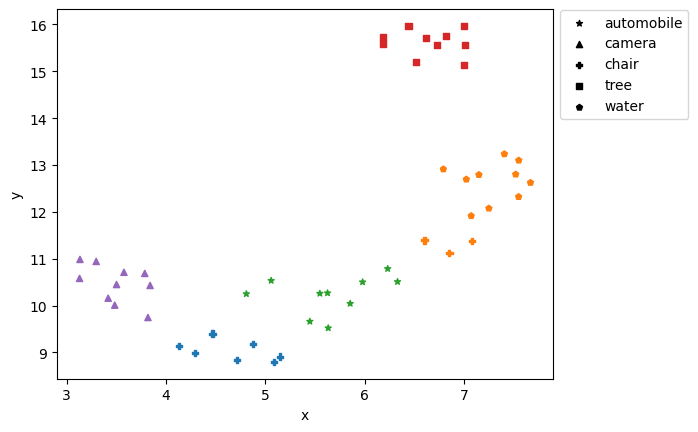
To display the resulting embeddings, we perform a dimensionality reduction step to keep only two components which can then be mapped to <x, y> in a 2-dimensional plot. Then, we use KMeans to group the embeddings into clusters which are represented using different colors. Different ground truth labels are represented using different markers.
This way, we can visually determine if the embeddings properly capture the meaning of a sentence – we should expect different fun facts about the same topic to be clustered together and thus have the same color in the visualization. We have to keep in mind that our main goal here is to visualize how well a model can separate the different topics. If we want to perform topic classification we would need a larger dataset with train and test splits for evaluation.
The code to do the visualization is relatively uninteresting, so no further explanation other than the code comments is provided:
def plot_embeddings(embeddings: np.ndarray, true_labels: list): """Performs dimensionality reduction and clustering, and plots embeddings. Dimensionality reduction is performed using UMAP, from the `umap-learn` package. Clustering is performed using KMeans. Different colors are used to indicate different clusters, and different markers are used to indicate different labels from the ground truth. """ # Normalize the embeddings. embeddings = preprocessing.normalize(embeddings) # Map labels to integers using ordinal encoding. label_map = {x: i for i, x in enumerate(sorted(set(true_labels)))} labels_int = [label_map[x] for x in true_labels] # Reduce the dimension of the embeddings to just two components. xy = umap.UMAP(random_state=0, n_components=2).fit_transform(embeddings) xy = pd.DataFrame(xy, columns=['x', 'y']) # Compute the clusters using KMeans. n_clusters = len(label_map) clusters = cluster.KMeans(n_clusters, n_init='auto').fit_predict(xy) # Try to map the same indices to the same clusters every time. cluster_map = {x: i for i, x in enumerate(dict.fromkeys(clusters))} # Assign a marker to each true label. marker_choices = ['*', '^', 'P', 's', 'p', 'X', 'D', 'H', 'v', 'o'] markers = [marker_choices[x] for x in label_map.values()] # Assign a color to each computed cluster. palette = list(mcolors.TABLEAU_COLORS.values()) xy['c'] = [palette[cluster_map[x]] for x in clusters] # Each marker needs to be plotted in a different step. ax = None plot_opts = dict(kind='scatter', x='x', y='y', s=20) for label, idx in label_map.items(): marker = markers[idx] xy_mask = np.array(labels_int) == idx df = pd.DataFrame(xy[xy_mask], columns=['x', 'y', 'c']) ax = df.plot(ax=ax, c=df['c'], marker=marker, label=label, **plot_opts)
Now that we have a way to visualize the results, let's compute the embeddings using the Universal Sentence Encoder model, available in TensorFlow Hub. First, we load the model and then we just need to feed the text to it – the outputs will be the embeddings:
import tensorflow_hub as hub # Load the model from tensorflow hub. model = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4") # Compute the embeddings for each sentence. embeddings = model(sentences_df.text) # Plot the resulting embeddings. plot_embeddings(embeddings.numpy(), sentences_df.label.tolist())
The resulting visualization shows us that these embeddings are mostly OK, but definitely has a hard time separating the topics from some of the sentences across the "automobile" and "chair", and in one instance even "water":
While there's different ways to overcome this issue, such as tuning the dimensionality reduction or clustering parameters, we risk overfitting our methodology to this particular set of data. Instead, we can try using a different, bigger model to produce the embeddings and see if the results improve. A good candidate is the Sentence T5 model, also available in TensorFlow Hub. Here we repeat the same process, but using the Sentence T5 model:
# The package tensorflow_text is required by ST5. import tensorflow_text import tensorflow_hub as hub # Load the model from tensorflow hub. model = hub.load('https://tfhub.dev/google/sentence-t5/st5-base/1') # Compute the embeddings for each sentence. embeddings = model(sentences_df.text)[0] # Plot the resulting embeddings. plot_embeddings(embeddings.numpy(), sentences_df.label.tolist())
This model results in only two instances in which a cluster contains sentences from multiple topics (mixing the topics of "chair" with "water"), which is a great deal considering that this can be achieved using nothing but commodity hardware and freely available open source models!
A lot has been written about large language models and their various capabilities, most notably the ability to generate text. However, most large language models are also capable of producing embeddings. Although they are likely better suited for larger document embeddings (some can handle thousands of words), we can also validate sentence embeddings. The PaLM API allows developers to easily produce embeddings from text using a simple HTTP endpoint, the documentation provides an example command using curl to obtain a response from the PaLM 2 large language model:
curl \ -H 'Content-Type: application/json' \ -d '{ "prompt": { "text": "Write a story about a magic backpack"} }' \ "https://generativelanguage.googleapis.com/v1beta2/models/text-bison-001:generateText?key=YOUR_API_KEY"
We can use a very similar HTTP POST query using the requests library to compute sentence embeddings:
# Use the gecko embedding model. model = 'models/embedding-gecko-001' # Define the HTTP endpoint URL using our API key. palm_api_root = 'https://generativelanguage.googleapis.com/v1beta2' palm_api_url = f'{palm_api_root}/{model}:embedText?key={palm_api_key}' # Compute the embeddings for each sentence. map_func = lambda x: requests.post(palm_api_url, json={'text': x}).json() embeddings = [map_func(x)['embedding']['value'] for x in sentences_df.text] # Plot the resulting embeddings. plot_embeddings(np.array(embeddings), sentences_df.label.tolist())
Alternatively, the google-generativeai pip package makes it even simpler to produce embeddings using the API transparently behind the scenes:
import google.generativeai as palm # Use the gecko embedding model. model = 'models/embedding-gecko-001' # Configure the library using our API key. palm.configure(api_key=palm_api_key) # Compute the embeddings for each sentence. map_func = lambda x: palm.generate_embeddings(model, x)['embedding'] embeddings = np.array([map_func(x) for x in sentences_df.text]) # Plot the resulting embeddings. plot_embeddings(embeddings, sentences_df.label.tolist())
Surprisingly, the output doesn't separate all the topics quite right into individual clusters. One possible explanation is that large language models are optimized for much larger pieces of text and can handle multiple languages, whereas the sentence embeddings we produced earlier used models that were specifically designed for shorter pieces of text and are English-only:
The PaLM API is not the only way to access the PaLM 2 large language model. Google Cloud customers can also use Vertex AI, which provides a very similar API. Similarly, requests to the endpoint can be made using HTTP POST requests directly:
import requests from google.colab import auth from oauth2client import client # Authenticate Colab instance and get Google Cloud credentials. auth.authenticate_user() creds = client.GoogleCredentials.get_application_default() # Build the API endpoint URL incrementally. model = 'models/textembedding-gecko' vertexai_root = 'https://us-central1-aiplatform.googleapis.com/v1' vertexai_project_url = f'{vertexai_root}/projects/{project_id}' vertexai_loc_url = f'{vertexai_project_url}/locations/us-central1' vertexai_model_url = f'{vertexai_loc_url}/publishers/google/{model}:predict' def map_func(text: str): access_token = creds.get_access_token().access_token payload = {'instances': [{'content': text}]} headers = {'Authorization': f'Bearer {access_token}'} res = requests.post(vertexai_model_url, json=payload, headers=headers) return res.json()['predictions'][0]['embeddings']['values'] embeddings = np.array([map_func(x) for x in sentences_df.text]) plot_embeddings(embeddings, sentences_df.label.tolist())
And, just like with the PaLM API, there's also a python library google-cloud-aiplatform which handles the HTTP calls behind the scenes for us:
import vertexai from vertexai.language_models import TextEmbeddingModel vertexai.init(project=project_id) model = TextEmbeddingModel.from_pretrained('textembedding-gecko@001') map_func = lambda x: model.get_embeddings([x])[0].values embeddings = np.array([map_func(x) for x in sentences_df.text]) plot_embeddings(embeddings, sentences_df.label.tolist())
As expected, since it's the exact same large language model behind the scenes, the results are very similar compared to those from the PaLM API:
It's important to note that embeddings, while extremely useful, will never be perfect. That's because the underlying information comes from natural language which is, by its very nature, imprecise, ambiguous and produces very noisy data. Embeddings are a very powerful tool that allow us to retrieve a purely numerical representation of the conceptual meaning of words, sentences, and entire documents in much more consistent ways than traditional methodologies such as keyword search.
Although we were able to achieve reasonable results with a very simple implementation in this blog post, deploying an AI-powered solution to production requires significantly more work including testing and, of course, ensuring responsible AI development.
The input data is available here and the full code can be run on Colab and is available here. You can also learn more about embeddings from the following resources: