In this blog post, we’ll focus on the key Responsible AI concepts that developers, specifically, need to know when deploying AI.
The term “Responsible AI” can be defined in numerous ways. For developers specifically, the concept refers to the safe deployment of any application that uses what's broadly considered to be AI, most notably bespoke and pre-trained machine learning models — including both when the models are used by an application directly or served via some API. Responsible AI also requires developers to consider privacy, avoiding unfair bias and accountability to people, all elements of deploying safe AI. Whether the use of AI is obvious or visible to the end user is irrelevant in this context, assuming the application even has a concrete end user.
Background
The concepts described in this blog post are largely based on previous work by well-established research and international institutions, including:
Each of those resources are well-worth a read in their own right, and it's also worth noting that this is not a comprehensive list. We’ve aggregated key ideas, summarizing them to offer a high-level view that is digestible and useful for developers. The goal is to equip you with helpful information as you make technical decisions, from a variety of trusted industry sources.
Lifecycle and Key Dimensions of an AI System, from the NIST RMF.
AI Actors, End Users, and Stakeholders
The entities that play a role in the lifecycle of an AI system can be subclassified into different types of actors in the AI ecosystem that we’ll describe in this post as AI actors, end users, and stakeholders.
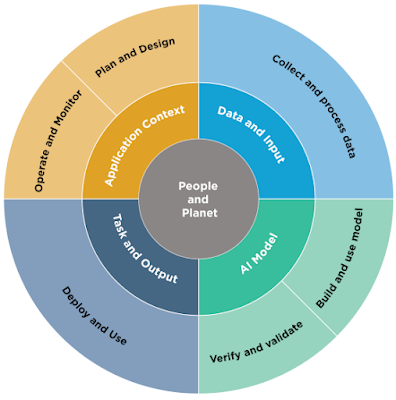
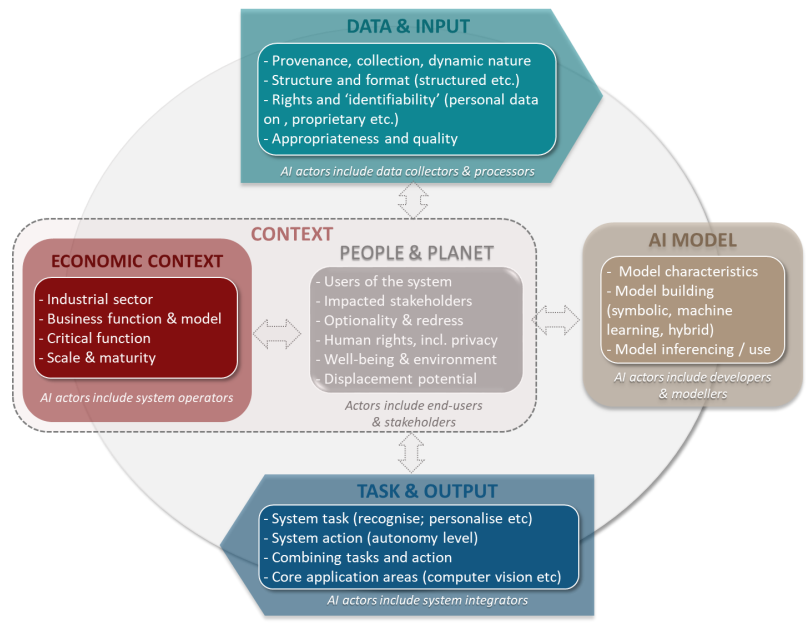
Key high-level dimensions of the OECD Framework for the Classification of AI Systems with illustrative examples.
AI Actors
This refers to the group of people that influence the AI system from the conceptual stage all the way to deployment. AI actors can be considered a pretty broad group, since it includes anyone involved in the data collection process, model research, development and testing, deployment and maintenance, etc. This group can also include policymakers, which may influence certain constraints or requirements involving all AI systems.
End Users
This group includes persons that interact with the AI system for a specific purpose. Determining who the end users are is not always obvious. For example, an AI-powered email spam detection system could have the email recipient as the end user if they can see what was flagged as spam. On the other hand, the same spam detection system could have a completely different group as the end users if the flagged emails are never shown to the recipient and instead are used as part of some data collection process, for instance to be analyzed as part of some other research.
Stakeholders
This refers to anyone and anything affected by the outcomes of the AI system directly or indirectly. It could be individual persons, animals or other living beings, groups, entire organizations, or even the environment as a whole. This is an extremely broad category, and what should be included in it is entirely dependent on the risks being assessed.
Risk and Safety Management
A key component of responsibility is the management of risk and safety. There are many potential definitions for those concepts, and there's no universally accepted standard definition. That said, in order to proceed, we should have some definition, however imperfect it may be.
For Responsible AI, safety is understood as the “absence of” risk. Risk and safety, of course, are not binary values, but rather the management of risk and safety is measured on a continuous scale. It is highly unlikely that there will be a complete absence of AI-related risks in any AI application deployment, and new risks arise with new technologies.
Risk is generally expressed in terms of risk sources, potential events, their consequences and their likelihood (ISO 31000:2018). As developers, we can't directly influence risk, but we can make choices that affect the components that risk is a function of. However, those choices rarely affect a single component in isolation; in most cases any given choice will result in a compromise affecting multiple components in different ways.
AI-generated images can have a high level of risk, because they may contain unsafe content, such as offensive imagery or deep fakes that could be used for misinformation purposes. A simple strategy to address that is ensuring a human reviews all images before showing them to users. Not even a "kitten safety officer" can fully mitigate the risks!
As an example to illustrate this, let's imagine a fictional autocomplete feature for a text editor in which the user can type the beginning of a sentence and an AI system will suggest how the sentence should be completed. Here, the source of risk is the AI model which produces outputs visible to the user. The potential events are sentence completion suggestions being harmful or inappropriate, which could range in severity (i.e. consequences) from low, such as by suggesting text with improper grammar, to high, such as by suggesting offensive or inappropriate language.
As developers, we could try to switch the source of risk by swapping the AI model with a different one, but that may in fact increase the resulting overall level of risk in the AI system if the model is, for example, more likely to output inappropriate language. We could also tweak the potential events by filtering outputs, providing multiple choices to the user, or only providing a suggestion when certain conditions are met that make it less likely to produce harmful outputs.
Trustworthiness
For an AI application to be considered trustworthy, certain criteria must be met. Characteristics of trustworthy AI systems include: safe, secure and resilient, explainable and interpretable, privacy-enhanced, fair with harmful bias managed, valid and reliable, and accountable and transparent. You can refer to the NIST AI RMF for more details about each of these characteristics.
Characteristics of a trustworthy AI system, as per the NIST AI RMF.
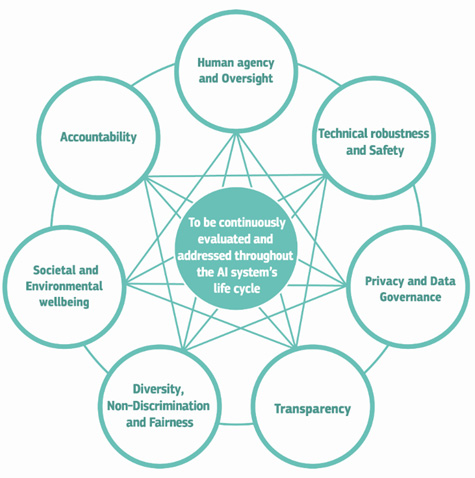
Similarly, the Ethics Guidelines for Trustworthy AI and its companion resource the EU ALTAI published by the High-Level Expert Group on Artificial Intelligence (AI HLEG) define trustworthy AI as lawful, ethical and robust. It also includes 7 key requirements that AI systems should meet to be deemed trustworthy: human agency and oversight; technical robustness and safety; privacy and data governance; transparency; diversity, non-discrimination, and fairness; societal and environmental wellbeing; accountability.
Key requirements for a trustworthy AI system, as per the EU ALTAI.
Trustworthy AI systems are inherently less risky, but the reverse is not always the case. An AI system could implement many mitigations for several types of risk making it safer for end users, but fail to incorporate many of the characteristics that would make it trustworthy such as not being secure, private, fair, or transparent. Naturally, being untrustworthy can also be considered a specific type of risk in which case trustworthiness and safety are aligned.
A responsible use of AI does not only mitigate risk, but it also increases the trustworthiness of the AI system by ensuring the presence of the characteristics of trustworthy AI.
Differences and Similarities with Traditional Software Risks
The NIST AI RMF provides an appendix stating differences between AI and traditional software risks, but there are also some similarities that can help developers conceptualize those new classes of AI risk and take steps to mitigate them. Typically, developers can take a similar approach to risk compared to how we solve other traditional problems in software development.
In the table below, we discuss how. On the left are the NIST’s descriptions of differences, and on the right are my observed similarities from the point of view of a developer:
| Differences between AI and traditional software risks (as stated in the NIST AI RMF) |
Similar risks and suggested approaches toward potential mitigations |
| The data used for building an AI system may not be a true or appropriate representation of the context or intended use of the AI system, and the ground truth may either not exist or not be available. Additionally, harmful bias and other data quality issues can affect AI system trustworthiness, which could lead to negative impacts. |
The business requirements provided to the software application developers may not be a true or appropriate representation of the actual application use case and intended use. |
| AI system dependency and reliance on data for training tasks, combined with increased volume and complexity typically associated with such data. |
Package and dependency management complexity, including specific and sometimes incompatible library versions. |
| Intentional or unintentional changes during training may fundamentally alter AI system performance. |
Intentional or unintentional changes during application development, such as memory management or garbage collection techniques, may fundamentally alter application performance. |
| Datasets used to train AI systems may become detached from their original and intended context or may become stale or outdated relative to deployment context. |
Business requirements used to develop a software application may become stale or outdated relative to the current user needs. |
| AI system scale and complexity (many systems contain billions or even trillions of decision points) housed within more traditional software applications. |
Large-scale projects developed over long periods of time can contain thousands of business rules, and large binaries can contain billions of assembly instructions. |
| Use of pre-trained models that can advance research and improve performance can also increase levels of statistical uncertainty and cause issues with bias management, scientific validity, and reproducibility. |
Use of third party libraries can advance software engineering and improve developer productivity but it can also cause issues with dependency management, lack of testing and reproducible builds, or packaging of applications. |
| Higher degree of difficulty in predicting failure modes for emergent properties of large-scale pre-trained models. |
Deployment of software in different hardware architectures such as x86, ARM and RISC-V also increases difficulty in predicting failure modes. |
| Privacy risk due to enhanced data aggregation capability for AI systems. |
Privacy risk due to software vulnerabilities, including those outside of the application's control. |
| AI systems may require more frequent maintenance and triggers for conducting corrective maintenance due to data, model, or concept drift. |
Businesses with frequently changing requirements might also require more frequent maintenance due to business rules that require updating. |
| Increased opacity and concerns about reproducibility. |
Transitive dependencies also increase opacity and lack of reproducible builds can also lead to operational concerns about reproducibility. |
| Underdeveloped software testing standards and inability to document AI-based practices to the standard expected of traditionally engineered software for all but the simplest of cases. |
Lack of proper testing culture and following of engineering best practices in some organizations can also lead to substandard products. |
| Difficulty in performing regular AI-based software testing, or determining what to test, since AI systems are not subject to the same controls as traditional code development. |
Certain types of software, such as UI components and telemetry systems, are also notoriously difficult to test. |
| Computational costs for developing AI systems and their impact on the environment and planet. |
Computational costs for applications in general have increased at a similar pace as hardware capabilities, for example in areas such as video transcoding, 3D rendering and particle-based simulations. |
| Inability to predict or detect the side effects of AI-based systems beyond statistical measures. |
Certain types of applications, such as mathematical models and physics simulations, can also be difficult to inspect beyond statistical measures. |
Implementation Details
After understanding the foundational components of Responsible AI systems, everything else is about implementation details. Unsurprisingly, this part is both the most challenging and also strictly dependent on the specific use case, which includes not only the AI system but also the governance structure and the organizations behind its deployment.
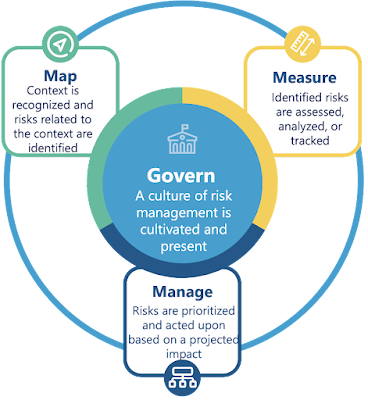
Here is where the different industry guidelines diverge and the focus goes from the technical concepts to the processes in which those concepts are applied. For example the NIST provides a playbook as a companion resource to the AI RMF.
NIST AI RMF Playbook core functions.
Using a similar approach, the EU ALTAI provides a self-assessment tool that will guide you through a set of questions to identify whether all the requirements for a trustworthy AI system are met.
Visualization of an assessment from the ALTAI online tool.
Another example of a different way to responsibly implement an AI system is the
pattern-oriented approach proposed by CSIRO, where a process to deploy AI applications can be refined and turned into a template, which can then be replicated in future AI deployments.
Ultimately, the decision on which specific approach to take is up to the individual business goals, organizations, and teams deploying the AI systems. We as developers can advocate for some over others, but the decision needs to involve all AI actors and take into account the end users and stakeholders.