Posted by Oscar Wahltinez, Developer Programs Engineer In this blog post, we’ll focus on the key Responsible AI concepts that develop...
Posted by Oscar Wahltinez, Developer Programs Engineer
Assuming that you have sufficiently available memory (40-50 GB of RAM) and are only interested in the locations of buildings (ignoring their footprints), you can just load the entire dataset as previously covered and then call pandas.DataFrame.sample() to obtain a random sample:
# DataFrame containing all data in-memory. df: pd.DataFrame = ... # Sample random elements from the dataset. sample_size = 100_000 sample = df.sample(sample_size)
Those drawbacks may be acceptable for your use case, but if you want to explore alternative trade-offs, read on.
This problem can be tackled from multiple angles, and each approach will make a series of trade-offs. It's your job as a scientist, researcher or developer to choose the appropriate set of trade-offs which will depend on your particular use case.
One way to look at this class imbalance problem is to acknowledge that the samples are clustered around big population centers. To avoid that problem, we can introduce a bias to our sample selection process and remove samples that are considered to be too close to each other. The simplest method would be to randomly draw samples from the dataset, compute the distance to all previously selected buildings, and only if a minimum distance threshold is met we add them to the selection. Here's what that might look like:
import pandas as pd from geopy.distance import great_circle # Read all buildings within the S2 cell with token 0ef. url_root = "gs://open-buildings-data/v2" poly_path = f"{url_root}/points_s2_level_4_gzip" df = read_pandas_csv(f"{poly_path}/0ef_buildings.csv.gz", compression="gzip") # Helper function to extract latitude and longitude from building objects. get_lat_lng = lambda x: (x["latitude"], x["longitude"]) selection = [] sample_size = 1_000 threshold_meters = 500 # Draw random samples until we have 1,000 buildings at least 500m apart. # `DataFrame.sample(frac=1)` is a shortcut used to shuffle the dataset. # NOTE: Don't do this unless you need very few samples. for _, building in df.sample(frac=1).iterrows(): latlng = get_lat_lng(building) # As soon as any distance does not meet the threshold stop computing them. distance_func = lambda x: great_circle(latlng, get_lat_lng(x)).meters if all(distance_func(x) >= threshold_meters for x in selection): selection.append(building.to_dict()) if len(selection) >= sample_size: break
A few things worth noting in the above code snippet:
Unfortunately, this is very slow. It may work well for a small amount of samples, but for the size needed for statistical analysis this is likely not performant enough. The good news is, there is yet another geospatial sampling method we can use.
A hash function maps an arbitrarily-sized set of inputs to a fixed-sized set of outputs. This is frequently used for strings and files, but the same concept can be applied to geospatial entities such as buildings. One way to do this is by dividing the region of interest into a grid, and then mapping each point within the grid to the corresponding cell that it falls under.
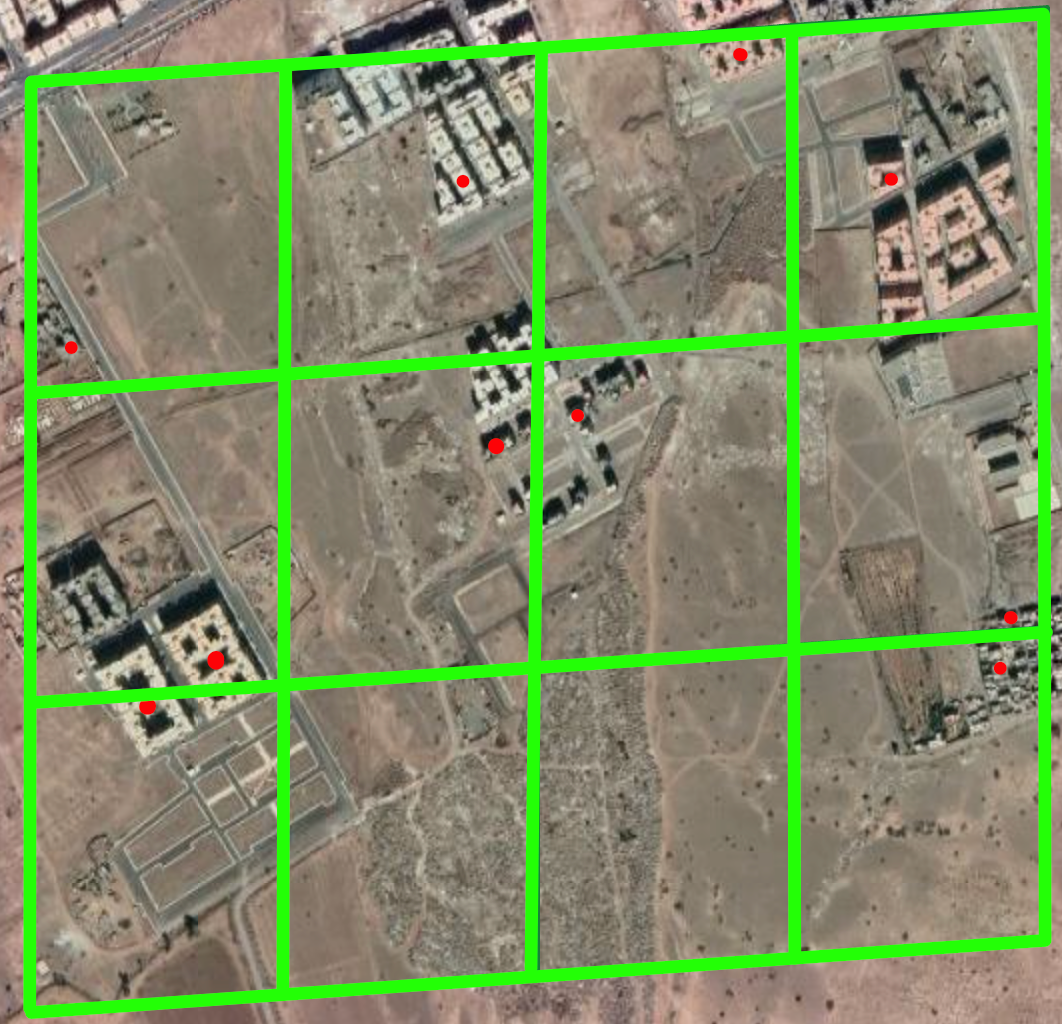
Assuming the hash function is relatively cheap to compute, we can enforce the geographical distribution bias in our sampling by ensuring that each individual cell in the grid contains at most a single sample. Here's an illustration of the methodology:
There are many possible hashing functions, the one chosen here is mapping from <lat, lng> coordinates to an S2 cell (from the S2 geometry library) of a predetermined level. Although there are no guarantees for the minimum distance between two samples, since they can be near the corresponding edges of two adjacent cells, in those cases the samples from the other neighboring cells will be farther apart – thus, on average, the minimum distance between a sample and its closest neighbor is expected to be relatively close to the average distance between neighboring cell centroids, assuming every cell produces a sample.
Here's an example implementation of this sampling methodology using the s2sphere Python package:
import s2sphere as s2 df: pd.DataFrame = ... get_lat_lng = lambda building: ... def s2_cell_at_lat_lng(lat, lng, level=30): """Helper function to retrieve S2 cell of <level> at <lat,lng> coordinates.""" latlng = s2.LatLng.from_degrees(lat, lng) return s2.CellId.from_lat_lng(latlng).parent(level) cell_level = 14 sample_size = 1_000 selection = [] cell_tokens = set() # Iterate over all (shuffled) buildings and add them to the selection if there are # no hash collisions. # NOTE: df.sample(frac=1) shuffles the DataFrame. for _, building in df.sample(frac=1).iterrows(): latlng = get_lat_lng(building) token = s2_cell_at_lat_lng(*latlng, level=cell_level).to_token() if token not in cell_tokens: cell_tokens.add(token) selection.append(building.to_dict()) if len(selection) >= sample_size: break
import scipy.spatial.distance from geopy.distance import great_circle # Compute a 2D matrix of pairwise distances. latlngs = [(x['latitude'], x['longitude']) for x in selection] distance_function = lambda a, b: great_circle(a, b).meters distances = scipy.spatial.distance.pdist(latlngs, metric=distance_function) distance_matrix = scipy.spatial.distance.squareform(distances) # Set all distances between a sample and itself to infinity, otherwise the # average minimum distance will be zero. distance_matrix[distance_matrix == 0] = float('inf') # Compute the mean distance between each sample and the closest pair. distance_matrix.min(axis=1).mean()
This produces an average minimum distance of 7,291 meters. Much more than 500 meters! That's because not every cell contains a building and we are only sampling 1.2% of the buildings in this particular cluster.
While the distance-based sampling methodology takes several minutes to finish, applying geospatial hashing completes its sampling in just a few seconds.
Although it takes a few seconds to complete, that's only for the processing of a single S2 cell cluster – and the Open Buildings dataset is divided into 129 clusters.
This is not a huge number, but learning how to parallelize the processing will come handy for potentially much larger future datasets. There are many ways to achieve this task, here we'll cover how to scale the processing of our data using Apache Beam.
[Input PCollection] | [Transform] | [Output Writer]
# Get all S2 cell tokens that contain buildings data. # NOTE: Reading files directly from GCS is faster than the http REST endpoint. url_root = "gs://open-buildings-data/v2" # url_root = "https://storage.googleapis.com/open-buildings-data/v2" tokens = read_pandas_csv(f"{url_root}/score_thresholds_s2_level_4.csv").s2_token # The polygon type can be "points" (centroid) or "polygon" (footprint). poly_type = "points" #@param ["points", "polygons"] # Create a list with all URLs that we must download data from. fnames = [f"{token}_buildings.csv.gz" for token in tokens] poly_path = f"{url_root}/{poly_type}_s2_level_4_gzip" urls = [f"{poly_path}/{fname}" for fname in fnames] # Save the header columns, which are shared across all clusters. columns = read_pandas_csv(urls[0], compression="gzip", nrows=0).columns
Next, we can write a function that will process each of those URLs and produce individual output records. To avoid the hassle of quoting fields, let's output the records in TSV format as a string. This largely builds on the previously defined methodology:
def process_token_url(url, columns=None): cell_level = 14 sample_size = 1_000 sample_count = 0 cell_tokens = set() # Iterate over all (shuffled) buildings and return them if there are # no hash collisions. df = read_pandas_csv(url, compression="gzip") for _, building in df.sample(frac=1).iterrows(): latlng = building["latitude"], building["longitude"] # Get the S2 cell token corresponding to <lat, lng>. token = s2_cell_at_lat_lng(*latlng, level=cell_level) if token not in cell_tokens: sample_count += 1 cell_tokens.add(token) # Return the building as a TSV line. yield "\t".join(str(building[col]) for col in columns) # Once we reach our desired sample size, we can stop. if sample_count >= sample_size: break
Finally, you can put everything together in a beam pipeline that outputs all records into sharded TSV files. Note that we use FlatMap instead of Map because process_token_url() outputs individual records, and we want all records from all dataset clusters to be in a single, flat list:
import apache_beam as beam # These options are used for testing purposes and work on Colab. To take # advantage of parallel processing, you should adjust them to your resources. opts = dict(direct_running_mode='multi_threading', direct_num_workers=8) with beam.Pipeline(options=beam.pipeline.PipelineOptions(**opts)) as pipeline: _ = ( pipeline | beam.Create(urls) | beam.FlatMap(process_token_url, columns=columns) | beam.io.WriteToText("output/data", ".tsv", header="\t".join(columns)) )
Using Beam's DirectRunner on a modest machine (by today's standards!) with 32 cores, processing and sampling all of the dataset clusters takes less than 10 minutes. Not too bad. 😎
The code used in this blog post is available as part of the following Github repositories and gists: