

Open Buildings Dataset: Downloading the Data
 Posted by Oscar Wahltinez, Developer Programs Engineer
Posted by Oscar Wahltinez, Developer Programs Engineer
 |
| An interactive map is available in the open buildings dataset site. |
What's in the dataset?
- The confidence field can be used to filter out low-confidence detections, or to perform weighted sampling depending on your applications.
- If you only care about the centroid, you can skip the polygon altogether and use the latitude and longitude fields.
- The geometry field describes the building footprint using the WKT (well-known text) format.
Geographical coverage
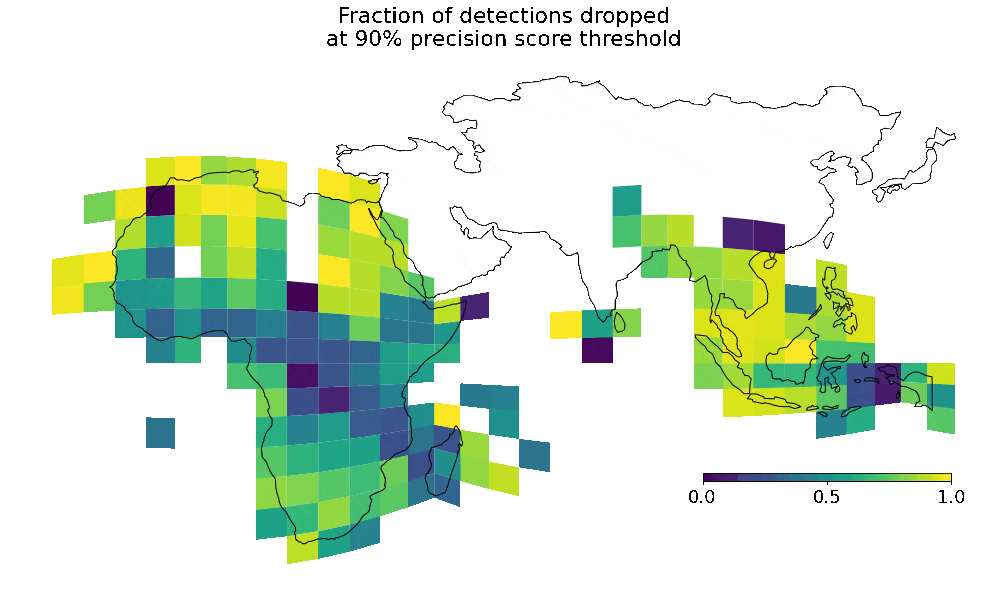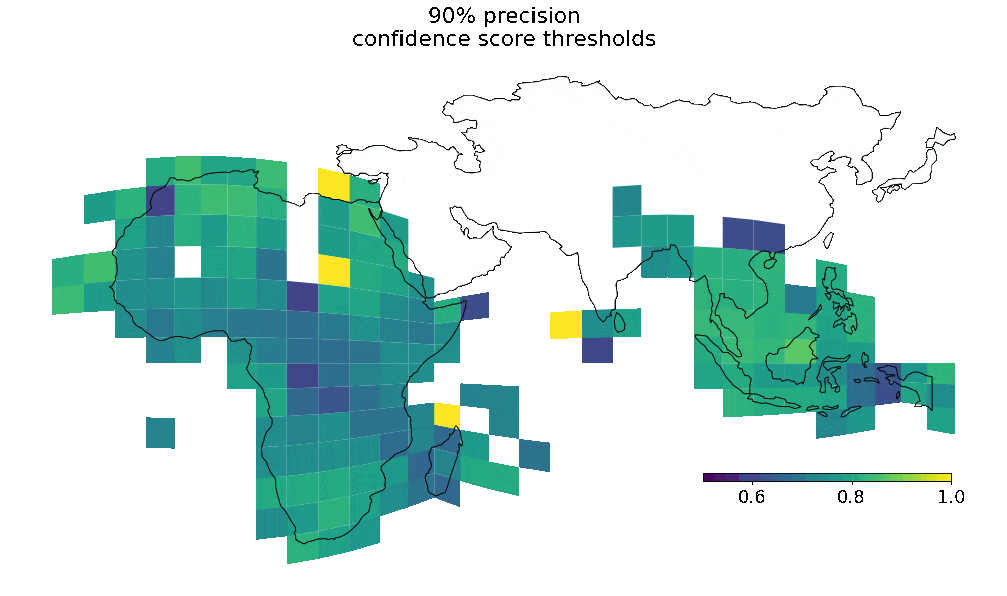 |
| Visualization of overall data coverage and 90% confidence building detection coverage. |
This means that, depending on the region of interest, you should use different thresholds to filter high-confidence detections.
Downloading compressed CSV files
 |
| Map with all areas covered by the dataset. |
If you just want to download the data for an individual cell, it's quite simple! The library pandas natively supports reading compressed CSV files:
The peak memory usage of that code is approximately 38GB (pro-tip: you can track that using the /usr/bin/time -v command), which sadly is larger than the maximum memory allocated to free Colab instances. While it's certainly possible to reduce the memory usage, it will likely come at the cost of speed.
Downloading Earth Engine FeatureCollection
Another way of accessing this dataset is by accessing the table available in the Earth Engine catalog in the form of a FeatureCollection. Generally speaking, you can access a feature collection trivially using the Earth Engine API:
Code and data availability