Posted by Oscar Wahltinez, Developer Programs Engineer In this blog post, we’ll focus on the key Responsible AI concepts that develop...
Last year, we announced the release of the GoEmotions dataset. In this blog post, we'll cover how the data can be downloaded, and how a simple model can be trained to classify fine-grained emotions given a piece of text.
The GoEmotions dataset is very easy to download! As per the Github repo's instructions, it's split across 3 CSV files:
URL_ROOT="https://storage.googleapis.com/gresearch/goemotions/data/full_dataset"
wget "$URL_ROOT/goemotions_1.csv"
wget "$URL_ROOT/goemotions_2.csv"
wget "$URL_ROOT/goemotions_3.csv"
Alternatively, if you are a TensorFlow user, you can get the data directly through TensorFlow Datasets:
import tensorflow_datasets as tfds
split = 'train' # or test, or validation
ds = tfds.load('goemotions', split=split)
The data is quite straightforward, as described in the Github repo. These are the fields:
To see the list of the labels, you can inspect the columns of the downloaded data or you can also get them directly from this file:
import urllib.request
emotions = urllib.request.urlopen(
'https://raw.githubusercontent.com/google-research/google-research'
'/master/goemotions/data/emotions.txt').read().decode('utf8').split('\n')
For the purposes of training, you may want to preprocess the data. Here's how you would get the different data splits and use one-hot encoding for the different emotions:
def preprocess_dataset(split, batch_size=128):
def one_hot_encode(x):
vec = tf.stack([x[emotion] for emotion in emotions], 0)
return x['comment_text'], tf.cast(vec, tf.uint8)
ds = ds.map(one_hot_encode, num_parallel_calls=tf.data.AUTOTUNE)
ds = ds.shuffle(buffer_size=batch_size * 10)
ds = ds.batch(batch_size, drop_remainder=False)
ds = ds.prefetch(buffer_size=tf.data.AUTOTUNE)
return ds
ds_splits = ['train', 'test', 'validation']
datasets = {split: preprocess_dataset(split) for split in ds_splits}
One of the most obvious uses of this dataset is to train a classifier to determine what emotions are depicted in a piece of text. There are many different models that can be used for natural language processing (NLP) tasks. A relatively safe choice is the BERT model, which is capable of turning free-form text into an embedding.
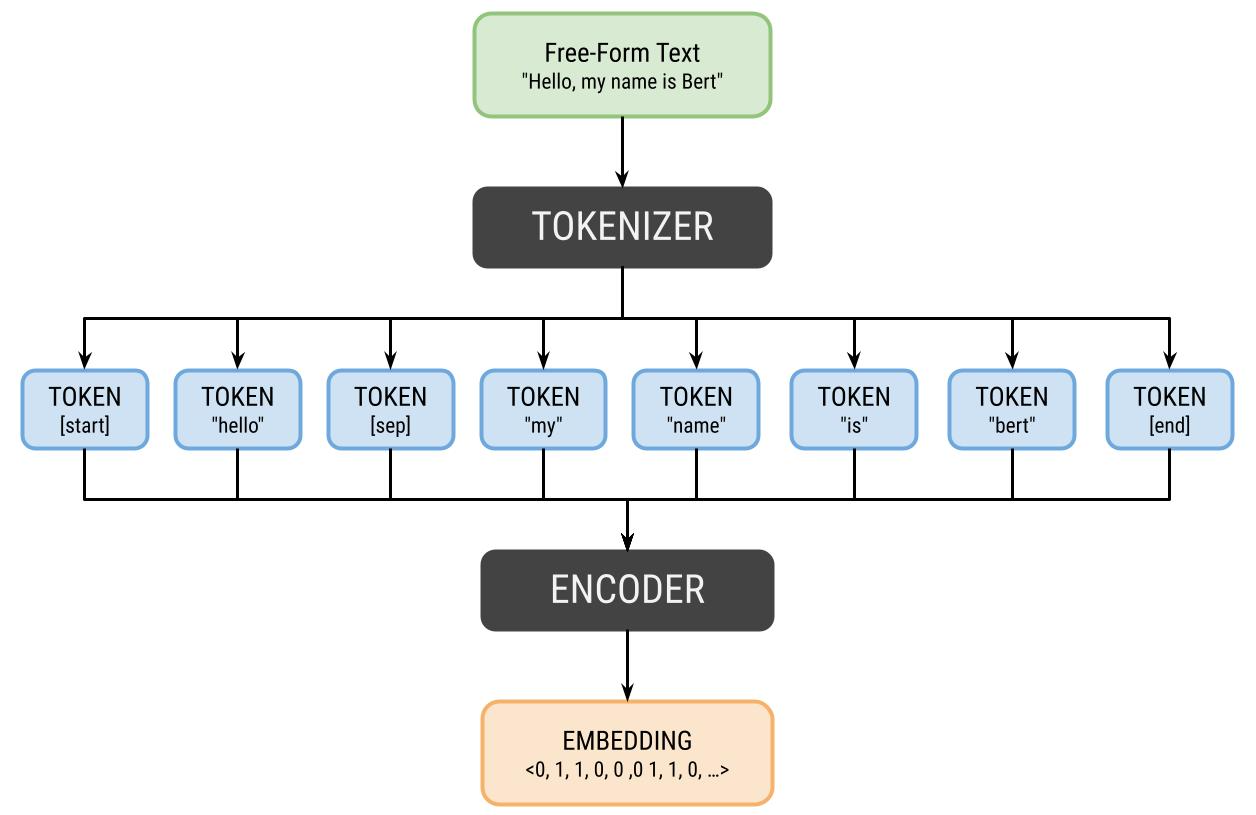
There are many different ways to preprocess text, and an even greater number of ways to encode the preprocessed text into an embedding. This is an illustration of a simplified version of BERT's architecture:
Using a pre-trained BERT model from TFHub and Keras' functional model API, you can create your own model based on BERT in just a few lines of code:
# Download assets from tfhub.
preprocessor = hub.KerasLayer(
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3')
encoder = hub.KerasLayer(
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/2',
trainable=True)
# Define a classifier with the BERT architecture that uses the encoder.
txt = tf.keras.layers.Input(shape=(), dtype=tf.string)
x = preprocessor(txt)
x = encoder(x)['pooled_output']
# Add a dropout regularization layer.
x = tf.keras.layers.Dropout(.1)(x)
# Add a final softmax layer for classification.
x = tf.keras.layers.Dense(len(labels), activation='softmax')(x)
model = tf.keras.Model(inputs=[txt], outputs=x)
Although extremely useful, the GoEmotions dataset is relatively small compared to many other NLP datasets. To encourage generalization and prevent overfitting, you can make use of the nlpaug library to perform data augmentation and synthetically increase the size of the dataset:
aug_spelling = naw.SpellingAug()
aug_random = naw.RandomWordAug(action='swap')
def iter_augmented_data(ds):
for x, y in iter(ds.unbatch()):
x = x.numpy().decode('utf8')
# Original text.
yield x, y
# Replace a random word by misspelling.
for x_aug in aug_spelling.augment(x, n=2):
yield x_aug, y
# Swap two words in input at random.
for x_aug in aug_random.augment(x, n=2):
gen_func = lambda: iter_augmented_data(datasets['train'])
ds_train = tf.data.Dataset.from_generator(
gen_func, output_types=(tf.string, tf.uint8))
ds_train = ds_train.batch(128).prefetch(tf.data.AUTOTUNE)
This way, for every real example in the dataset, you are generating two additional synthetic examples with a spelling mistake in a randomly chosen word and two more with two randomly chosen words swapped in the text.
While this might seem like a pretty crude technique, it works very well because it will encourage a model to learn that a word and its possible misspellings should map to similar embeddings. Similarly, it will also encourage the trained model to have a similar understanding for a sentence and a variation with its words slightly out of order.
With all the pieces in place, you can fine-tune the BERT model using the battle-tested Keras API:
optimizer = tf.keras.optimizers.Adam(learning_rate=1E-4)
metrics = [tf.keras.metrics.CategoricalAccuracy('accuracy', dtype=tf.float32)]
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=False)
model.compile(optimizer, loss, metrics=metrics)
model.fit(datasets['train'], validation_data=datasets['validation'], epochs=5)
After a couple of hours of training time (using a GPU-accelerated Colab runtime), you will have a classifier that uses the BERT architecture and is capable of somewhat-accurately determining the emotions depicted in a piece of text. Inspecting some of the predictions for unseen pieces of text from the test subset can be helpful in evaluating the model:
sentences, y_true_batch = next(datasets['test'].as_numpy_iterator())
y_pred_batch = model.predict(tf.constant(sentences))
for sentence, y_true, y_pred in zip(sentences, y_true_batch, y_pred_batch):
true_labels = [emotions[i] for i, x in enumerate(y_true) if x > .5]
pred_labels = [emotions[i] for i, x in enumerate(y_pred) if x > .5]
print('True labels:', true_labels)
print('Predicted labels:', pred_labels)
print(sentence.decode('utf8'), '\n')
In many cases, the model is uncertain of the classification (no class has a value higher than 0.5) and it does not predict any emotions. In many others, the prediction is wrong according to the dataset but arguably it could be considered a pretty decent classification:
Doesn't mean we can't improve on what we have
Disapproval
Neutral
Da real MVP
Admiration
I bet you could get away with this at work just fine.
Approval
Optimism
it is actually called a mechanical bull
Bless u x
Caring
What are the Four Agreements?
Curiosity
So creepy. Made me check my locks.
Annoyance, Disgust
Fear
The code used in this blog post is available as part of the following Github repositories and gists:
Models and data can be found in the following HugginFace spaces: